
Introduction
In the previous post we used the OCLC WorldCat Identities database to learn more about Frank N. Meyer, a botanist who made a USDA-sponsored expedition to South China, 1916-18. We requested that the server return information to us that had been marked up with XML, then extracted unique identifiers for other identities in the database that are linked to the record for Meyer. We also used a package called Graphviz to visualize the core of the network connecting Meyer to his associates. If you haven’t worked through that post, you should do so before trying this one.
A spider (or ‘crawler’ or ‘bot’) is a program that downloads a page from the Internet, saves some or all of the content, extracts links to other webpages, then retrieves and processes those in turn. Search engine companies employ vast numbers of spiders to maintain up-to-date maps of the web. Although spidering on the scale of the whole web is a difficult problem–and one that requires an elaborate infrastructure to solve–there are many cases when more limited spidering can play an important role in the research process. Here we will develop a surprisingly simple Bash script to explore and visualize a tiny region of the WorldCat Identities database.
Our algorithm in plain English
When coming up with a new program, it helps to alternate between top-down and bottom-up thinking. In the former case, you try to figure out what you want to accomplish in the most basic terms, then figure out how to accomplish each of your goals, sub-goals, and so on. That is top-down. At the same time, you keep in mind the stuff you already know how to do. Can you combine two simpler techniques to accomplish something more complicated? That is bottom-up.
Here is a description of what we want our spider to do:
- repeat the following a number of times
- get a unique identifier from a TO-DO list, make a note of it, then move it to a DONE list
- retrieve the web page for that ID and save a copy
- pull out any linked identifiers from the web page
- keep track of links between the current identifier and any associated identifiers so we can visualize them
- if any of the linked identifiers are not already in the DONE list, add them to the TO-DO list
- pause for a while
As we look at this description of the spider, it is clear that we already know how to do some of these things. We can probably use a for loop to repeat the process a number of times. We know how to retrieve an XML webpage from the WorldCat Identities database, save a copy and extract the associated identities from it. We also have a basic idea of how to graph the resulting network with Graphviz. Let’s build our spidering script one step at a time.
The main loop
In our first version of the program, we include the for loop and use comments to sketch out the rest of the structure. Use a text editor (like atom or vi) to write the following script, save it as spider-1.sh, then change permissions to 744 with chmod and try running it.
#! /bin/bash
for i in {1..10}
do
# if TODO list is not empty then do the following
# get first LCCN from TODO list and store a copy
echo "Processing $i"
# remove LCCN from TODO list
# append LCCN to DONE list
# retrieve XML page for LCCN and save a local copy
# get personal name for LCCN
# pull out LCCNs for associated ids and get personal names
# save links between LCCNs in GRAPH file
# if LCCNs for assoc ids are not in DONE list, add to TODO list
# sleep 2
done
The sleep command will pause between downloads, so we don’t hammer the OCLC server. For now, we have commented it out, however, so our tests run quickly. We don’t need to enable it until we are actually contacting their server. Note that we use indenting to help us keep track of which blocks of commands are nested inside of other blocks.
The TODO list
We will use external files to keep track of which LCCNs we have already processed, which ones we still need to process, and which links we have discovered between the various identities in the WorldCat database. Let’s start with the list of LCCNs that we want to process. We are going to keep these in a file called spider-to-do.txt. Create this file with the command
echo "lccn-n83-126466" > spider-to-do.txt
Make a copy of spider-1.sh called spider-2.sh and edit it so that it looks like the following.
#! /bin/bash
for i in {1..10}
do
# if TODO list is not empty then do the following
if [ -s spider-to-do.txt ]
then
# get first LCCN from TODO list and store a copy
lccn=$(head -n1 spider-to-do.txt)
echo "Processing $i, $lccn"
# remove LCCN from TODO list
sed -i '1d' spider-to-do.txt
# append LCCN to DONE list
echo $lccn >> spider-done.txt
# retrieve XML page for LCCN and save a local copy
# get personal name for LCCN
# pull out LCCNs for associated ids and get personal names
# save links between LCCNs in GRAPH file
# if LCCNs for assoc ids not in DONE list, add to TODO list
# sleep 2
fi
done
Note that we have added the logic which tests to make sure that our TODO list is not empty. This uses a primary expression which will be true if the spider-to-do.txt file exists and its size is greater than zero. We have also added code to get the first LCCN in the TODO list and save a copy in a variable called lccn. Using sed and echo we remove the LCCN from the TODO list and append it to the DONE list. Finally, note that we modified the echo statement so that it tells us which LCCN the script is currently processing. Check the permissions for spider-2.sh and try executing it. Make sure that you understand that it executes the for loop ten times, but that the if statement is only true once (since there is only one entry in spider-to-do.txt. So we only see the output of echo once.
Retrieving a webpage
The next step is to retrieve the XML version of the WorldCat Identities page for the current LCCN and extract the personal name for the identity. Make a copy of spider-2.sh called spider-3.sh and modify it so it looks as follows.
#! /bin/bash
for i in {1..10}
do
# if TODO list is not empty then do the following
if [ -s spider-to-do.txt ]
then
# get first LCCN from TODO list and store a copy
lccn=$(head -n1 spider-to-do.txt)
echo "Processing $i, $lccn"
# remove LCCN from TODO list
sed -i '1d' spider-to-do.txt
# append LCCN to DONE list
echo $lccn >> spider-done.txt
# retrieve XML page for LCCN and save a local copy
wget "http://www.worldcat.org/identities/"${lccn}"/identity.xml" -O ${lccn}.xml
# get personal name for LCCN
currname=$(xmlstarlet sel -T -t -m "/Identity/nameInfo" -o "\"" -v "rawName/suba" -o "\"" -n ${lccn}.xml | tr -d ' ')
echo "Current name $currname"
# pull out LCCNs for associated ids and get personal names
# save links between LCCNs in GRAPH file
# if LCCNs for assoc ids not in DONE list, add to TODO list
# sleep 2
fi
done
As in the previous post, we use wget to retrieve the file and xmlstarlet to extract information from it. We also use the echo command to display the personal name of the LCCN we are processing.
Before we try running this version of our spider, it will be handy to have a small script to reset our spider so we can run it again. Use a text editor to enter the following script and save it as reset-spider.sh. Change the permissions to 744 and execute it, then execute spider-3.sh. Note that the reset script will notify you that some files don’t exist. That’s OK, as they will exist eventually.
#! /bin/bash echo "lccn-n83-126466" > spider-to-do.txt rm spider-done.txt rm spider-graph* rm lccn*xml
You should now have a file called lccn-n83-126466.xml which was downloaded from the WorldCat Identities database. Your spider-to-do.txt file should be empty, and your spider-done.txt file should contain the LCCN you started with. You can try resetting the spider and running it again. You should get the same results, minus a few warning messages from the reset script.
Associated identities and personal names
Next we need to extract the associated identities for the LCCN we are processing, and get personal names for each. Make a copy of spider-3.sh called spider-4.sh and edit it so that it looks like the following. As before, we use the echo command to have a look at the variables that we are creating.
#! /bin/bash
for i in {1..10}
do
# if TODO list is not empty then do the following
if [ -s spider-to-do.txt ]
then
# get first LCCN from TODO list and store a copy
lccn=$(head -n1 spider-to-do.txt)
echo "Processing $i, $lccn"
# remove LCCN from TODO list
sed -i '1d' spider-to-do.txt
# append LCCN to DONE list
echo $lccn >> spider-done.txt
# retrieve XML page for LCCN and save a local copy
wget "http://www.worldcat.org/identities/"${lccn}"/identity.xml" -O ${lccn}.xml
# get personal name for LCCN
currname=$(xmlstarlet sel -T -t -m "/Identity/nameInfo" -o "\"" -v "rawName/suba" -o "\"" -n ${lccn}.xml | tr -d ' ')
echo "Current name $currname"
# pull out LCCNs for associated ids and get personal names
associd=$(xmlstarlet sel -T -t -m "/Identity/associatedNames/name" -v "normName" -n ${lccn}.xml | grep 'lccn')
echo "Associated LCCNs"
echo $associd
assocname=$(xmlstarlet sel -T -t -m "/Identity/associatedNames/name" -o "\"" -v "rawName/suba" -o "\"" -n ${lccn}.xml | tr -d ' ')
echo "Associated names"
echo $assocname
# save links between LCCNs in GRAPH file
# if LCCNs for assoc ids not in DONE list, add to TODO list
# sleep 2
fi
done
The final version of the spider
We have two remaining problems that we need to solve in order to get our spider up and running. First, we want to save all of the links between the various identities in a file so that we can visualize them with graphviz. This involves looping through the assocname array with a for loop, and appending each link to a file that we are going to call spider-graph.dot. The second problem is to add LCCNs to our TODO list, but only if we haven’t already DONE them. We will use an if statement and the fgrep command to test whether the spider-done.txt file already contains an LCCN, and if not, append it to spider-to-do.txt. Copy the spider-4.sh file to a version called spider-final.sh, and edit it so that it looks as follows. Note that we are hitting the WorldCat Identities database repeatedly now, so we need to uncomment the sleep command.
#! /bin/bash
for i in {1..10}
do
# if TODO list is not empty then do the following
if [ -s spider-to-do.txt ]
then
# get first LCCN from TODO list and store a copy
lccn=$(head -n1 spider-to-do.txt)
echo "Processing $i, $lccn"
# remove LCCN from TODO list
sed -i '1d' spider-to-do.txt
# append LCCN to DONE list
echo $lccn >> spider-done.txt
# retrieve XML page for LCCN and save a local copy
wget "http://www.worldcat.org/identities/"${lccn}"/identity.xml" -O ${lccn}.xml
# get personal name for LCCN
currname=$(xmlstarlet sel -T -t -m "/Identity/nameInfo" -o "\"" -v "rawName/suba" -o "\"" -n ${lccn}.xml | tr -d ' ')
echo "Current name $currname"
# pull out LCCNs for associated ids and get personal names
associd=$(xmlstarlet sel -T -t -m "/Identity/associatedNames/name" -v "normName" -n ${lccn}.xml | grep 'lccn')
echo "Associated LCCNs"
echo $associd
assocname=$(xmlstarlet sel -T -t -m "/Identity/associatedNames/name" -o "\"" -v "rawName/suba" -o "\"" -n ${lccn}.xml | tr -d ' ')
echo "Associated names"
echo $assocname
# save links between LCCNs in GRAPH file
for a in ${assocname[@]}
do
echo " "${currname}" -> "${a}";" >> spider-graph.dot
done
# if LCCNs for assoc ids not in DONE list, add to TODO list
for a in ${associd[@]}
do
if ! fgrep -q ${a} spider-done.txt
then
echo ${a} >> spider-to-do.txt
fi
done
sleep 2
fi
done
Reset the spider, then try running the final version. When it finishes running, you should have ten XML files in your directory. Use the less command to explore them, and the spider-to-do.txt, spider-done.txt and spider-graph.dot files.
Visualizing the network of identities
Now we can write a very small script to visualize the links between identities. Save the following as graph-spider.sh, change the permissions to 744 and execute it. Note that we are adding some formatting commands to our Graphviz file so that the nodes look a particular way. You can experiment with changing these to suit yourself.
#! /bin/bash
echo "digraph G{" > spider-graph-temp.dot
echo " node [color=grey, style=filled];" >> spider-graph-temp.dot
echo " node [fontname=\"Verdana\", size=\"20,20\"];" >> spider-graph-temp.dot
cat spider-graph.dot | sort | uniq >> spider-graph-temp.dot
echo "}" >> spider-graph-temp.dot
neato -Tpng -Goverlap=false spider-graph-temp.dot > spider-graph.png
display spider-graph.png &
The resulting network graph looks something like this:
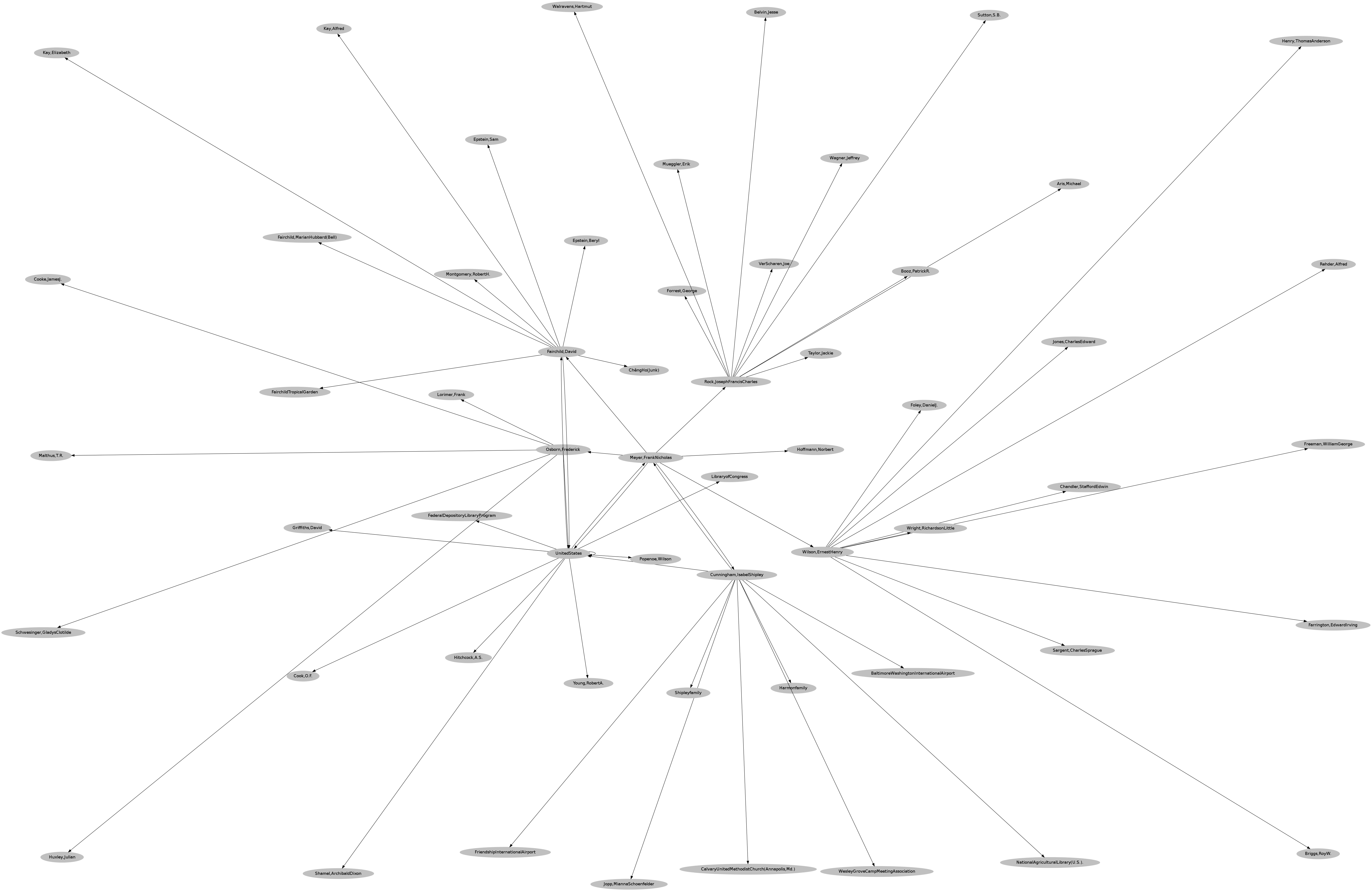
Why store the spider’s memory in external files?
If you have some experience with programming, you may be wondering why I chose to store the TODO and DONE lists in external files, rather than in memory in the form of Bash script variables. Note that when you finish running the spider for the first time, you have ten XML files in your current directory and a bunch of stuff in your spider-to-do.txt, spider-done.txt and spider-graph.dot files. In fact, you can resume the spidering process by simply running spider-final.sh again. New XML files will be added to your current directory, and the TODO and DONE lists and GRAPH file will all be updated accordingly. If you want to restart at any point, you can always run the reset script. If you find that your spider is getting stuck exploring part of the network that is not of interest, you can also add LCCNs to the DONE list before you start the spider. Using external files to store the state of the spider makes it very easy to restart it. This would be more difficult if the spider’s process were stored in memory instead.






You must be logged in to post a comment.