
Introduction
In previous posts we started with the URLs for particular online resources (books, collections, etc.) without worrying about where those URLs came from. Here we will use a variety of tools for locating primary and secondary sources of interest and keeping track of what we find. We will be focusing on the use of web services (also known as APIs or application programming interfaces). These are online servers that respond to HTTP queries by sending back text, usually marked up with human- and machine-readable metadata in the form of XML or JSON (JavaScript Object Notation). Since we’ve already used xmlstarlet to parse XML, we’ll get various web services to send us XML-formatted material.
Setup and Installation
In order to try the techniques in this blog post, you will need to sign up for (free) developer accounts at OCLC and Springer. First, OCLC. Go to this page and create an account. The user name that you choose will be your “WorldCat Affiliate ID” when you access OCLC web services. Once you have a user name and password for OCLC, go to the WorldCat Basic API site and log in there. The go to the Documentation page and on the left hand side menu you will see an entry under WorldCat Basic that reads “Request an API key”. This will take you to another site where you choose the entry “Sign in to Service Configuration”. Use your OCLC user name and password to sign in. On the left hand side of this site is a link for “Web Service Keys” -> “Request Key”. On the next page choose “Production” for the environment, “Application hosted on your server” for the application type, and “WorldCat Basic API” for the service. You will then be taken to a second page where you have to provide your name, email address, country, organization, web site and telephone number. Once you have accepted the terms, the system will respond by giving you a long string of letters and numbers. This is your wskey, which you will need below.
Second, Springer. Go to this page and create an account. Once you have registered, generate an API key for Springer Metadata. You will need to provide a name for your app, so choose something meaningful like linux-command-line-test. Make a note of the key, as we will be using this web service below.
Start your windowing system and open a terminal and web browser. I am using Openbox and Iceweasel on Debian, but these instructions should work for most flavors of Linux. In Iceweasel choose Tools -> Add-ons and install JSONView. Restart your browser when it asks you to.
You will also need the Zotero extension for your browser (if it is not already installed). In the browser, go to http://www.zotero.org and click the “Download Now” button, followed by the “Zotero 4.0 for Firefox” button. You will have to give permission for the site to install the extension in your browser. Once the extension has been downloaded, click “Install Now” then restart your browser. If you haven’t used Zotero before, spend some time familiarizing yourself with the Quick Start Guide.
Using Zotero to manage bibliographic references in the browser
In the browser, try doing some searches in the Internet Archive, Open WorldCat, and other catalogs. Use the item and folder icons in the URL bar to automatically add items to your Zotero collection. This can be a great time saver, but it is a good idea to get in the habit of looking at the metadata that has been added and making sure that it is clean enough for your own research purposes.
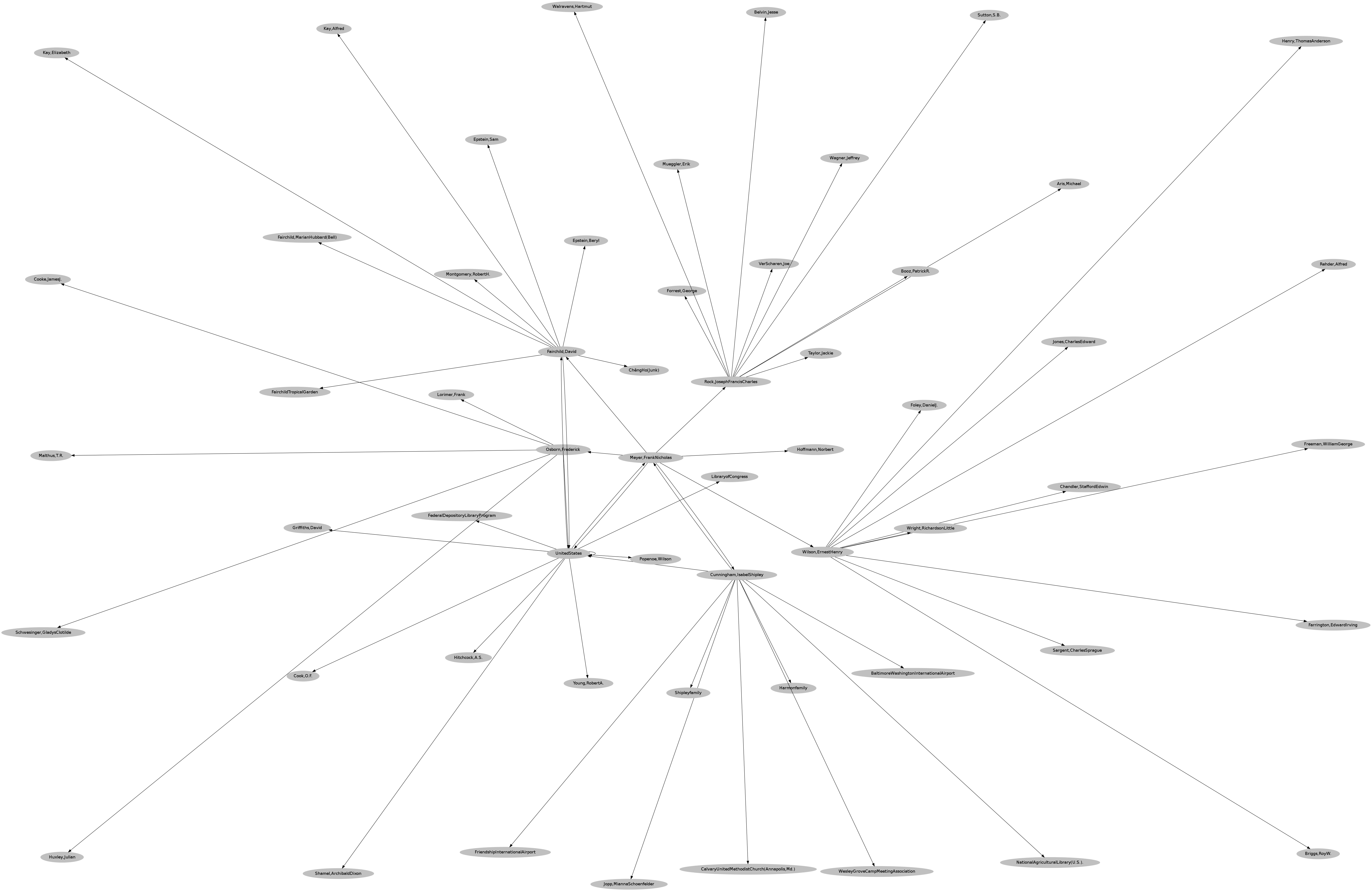
If you register for an account at Zotero.org, you can automatically synchronize your references between computers, create an offsite backup of your bibliographic database, and access your references using command line tools. For the purposes of this post, you can use a small sample bibliography that I put on the Zotero server at https://www.zotero.org/william.j.turkel/items/collectionKey/JPP66HBN. My Zotero user ID, which you will need for some of the commands below, is 31530.
Querying the Zotero API
The Zotero server has an API which can be accessed with wget. The results will be returned in the Atom syndication format, which is XML-based, so we can parse it with xmlstarlet. Let’s begin by getting a list of the collections which I have synchronized with the Zotero server. The –header option tells wget that we would like to include some additional information that is to be sent to the Zotero server. The Zotero server uses this message to determine which version of the API we want access to. We store the file that the Zotero server returns in collections.atom, then use xmlstarlet to pull out the fields feed/entry/title and feed/entry/id. Note that the Atom file that the Zotero server returns actually contains two XML namespaces (learn more here) so we have to specify which one we are using with the -N option.
wget --header 'Zotero-API-Version: 2' 'https://api.zotero.org/users/31530/collections?format=atom' -O collections.atom
less collections.atom
xmlstarlet sel -N a="http://www.w3.org/2005/Atom" -t -m "/a:feed/a:entry" -v "a:title" -n -v "a:id" -n collections.atom
Since there is only one collection, we get a single result back.
botanical-exploration
http://zotero.org/users/31530/collections/JPP66HBN
Now that we know the ID for the botanical-exploration collection, we can use wget to send another query to the Zotero API. This time we request all of the items in that collection. We can get a quick sense of the collection by using xmlstarlet to pull out the item titles and associated IDs.
wget --header 'Zotero-API-Version: 2' 'https://api.zotero.org/users/31530/collections/JPP66HBN/items?format=atom' -O items.atom
less items.atom
xmlstarlet sel -N a="http://www.w3.org/2005/Atom" -t -m "/a:feed/a:entry" -v "a:title" -n -o " " -v "a:id" -n items.atom > items-title-id.txt
less items-title-id.txt
A web page bibliography
We can also request that the Zotero server send us a human-readable bibliography if we want. Use File -> Open File in your browser to view the biblio.html file.
wget --header 'Zotero-API-Version: 2' 'https://api.zotero.org/users/31530/collections/JPP66HBN/items?format=bib' -O biblio.html
Note that each of our sources has an associated URL, but that there are no clickable links. We can fix this easily with command line tools. First we need to develop a regular expression to extract the URLs. We want to match everything that begins with “http”, up to but not including the left angle bracket of the enclosing div tag. We then use sed to remove the trailing period from the citation.
less biblio.html
grep -E -o "http[^<]+" biblio.html | sed 's/.$//g'
That looks good. Now we want to rewrite each of the URLs in our biblio.html file with an HTML hyperlink to that address. In other words, we have a number of entries that look like this
http://archive.org/details/jstor-1643175.</div>
and we want them to look like this
<a href="http://archive.org/details/jstor-1643175">http://archive.org/details/jstor-1643175</a>.</div>
Believe it or not, we can do this pretty easily with one sed command. The -r option indicates that we want to use extended regular expressions. The \1 pattern matches the part of the regular expression that is enclosed in parentheses. Use diff on the two files to see the changes that we’ve made, then open biblio-links.html in your browser. Each of the URLs is now a clickable link.
sed -r 's/(http[^<]+)\.</<a href="\1">\1<\/a>.</g' biblio.html > biblio-links.html
diff biblio.html biblio-links.html
Getting more information for one item
We can ask Zotero to send us more information about a particular item in the collection. Using the command below, we request the details for Isabel Cunningham’s Frank N. Meyer, Plant Hunter in Asia.
wget --header 'Zotero-API-Version: 2' 'https://api.zotero.org/users/31530/items/RJS46ARB?format=atom' -O cunningham.atom
less cunningham.atom
Note that the fields in cunningham.atom that contain bibliographic metadata (creator, publisher, ISBN, etc.) are stored in an HTML div within the XML content tag. We can use xmlstarlet to pull these fields out, but we have to pay attention to the XML namespaces. We start by creating an expression to pull out the XML content tag.
xmlstarlet sel -N a="http://www.w3.org/2005/Atom" -t -m "/a:entry" -v "a:content" -n cunningham.atom
To get access to the material inside the HTML tags, we add a second namespace to our xmlstarlet expression as follows. Note that we also have to specify the attribute for the HTML tr tag.
xmlstarlet sel -N a="http://www.w3.org/2005/Atom" -N x="http://www.w3.org/1999/xhtml" -t -m "/a:entry/a:content/x:div/x:table/x:tr[@class='ISBN']" -v "x:td" -n cunningham.atom
There are two ISBNs stored in that field.
0813811481 9780813811482
To make sure you understand how the XML parsing works, try modifying the expression to extract the year of publication and other fields of interest.
Getting information with an ISBN
OCLC has a web service called xISBN which allows you to submit an ISBN and receive more information about the work, including related ISBNs, the Library of Congress Control Number (LCCN) and a URL for the item’s WorldCat page. To use this service you do not need to provide an API key, but you do need to include your WorldCat Affiliate ID. So in the commands below, be sure to replace williamjturkel (which is my WorldCat Affiliate ID) with your own. Let’s request more information about the Cunningham book using the 10-digit ISBN we extracted above, 0813811481. First we will write a short Bash script to interact with the service. We will call this script get-isbn-editions.sh.
#!/bin/bash
affiliateid="williamjturkel"
isbn=$1
format=$2
wget "http://xisbn.worldcat.org/webservices/xid/isbn/"${isbn}"?method=getEditions&format="${format}"&fl=*&ai="${affiliateid} -O "isbn-"${isbn}"."${format}
Next we use our script to call the web service three times, asking for the information to be returned in text, CSV and XML formats. We can use less to have a look at each of the three files, but if we wanted to parse out specific information, we might use csvfix for the CSV file and xmlstarlet for the XML file.
chmod 744 get-isbn-editions.sh
./get-isbn-editions.sh "0813811481" "txt"
./get-isbn-editions.sh "0813811481" "csv"
./get-isbn-editions.sh "0813811481" "xml"
less isbn-0813811481.txt
less isbn-0813811481.csv
less isbn-0813811481.xml
Let’s parse the LCCN and WorldCat URL out of the XML file.
xmlstarlet sel -t -v "//@lccn" -n isbn-0813811481.xml
xmlstarlet sel -t -v "//@url" -n isbn-0813811481.xml
The system responds with
83012920
http://www.worldcat.org/oclc/715401288?referer=xid
The URL allows us to see the WorldCat webpage for our book in a browser. With the LCCN, one thing that we can do is to query the Library of Congress catalog and receive a MODS (Metadata Object Description Schema) record formatted as XML. Note that the MODS file contains other useful information, like the Library of Congress Subject Heading fields (LCSH). We can parse these out with xmlstarlet. Note that the parts of the subject heading fields are jammed together. Can you modify the xmlstarlet command to fix this?
wget "http://lccn.loc.gov/83012920/mods" -O cunningham.modsxml
less cunningham.modsxml
xmlstarlet sel -N x="http://www.loc.gov/mods/v3" -t -v "/x:mods/x:subject[@authority='lcsh']" -n cunningham.modsxml
You can also import from a MODS file directly into Zotero. Suppose that you’re doing some command line searching and come across E. H. M. Cox’s 1945 Plant-Hunting in China (LCCN=46004786). Once you have imported the MODS XML file with wget, you can use the Zotero Import command (under the gear icon) to load the information directly into your bibliography.
wget "http://lccn.loc.gov/46004786/mods" -O cox.modsxml
As we have seen in previous posts, many of these fields serve as links between data sets, allowing us to search or spider the ‘space’ around a particular person, institution, subject, or work.
Querying the WorldCat Basic API
In addition to querying by ISBN, OCLC has a free web service that allows us to search the WorldCat catalog. In this case you will need to provide your wskey when you send requests. Use vi to create a file called oclc-wskey.txt and save your wskey in it.
The WorldCat Basic API allows you to send queries to WorldCat from the command line. Create the following Bash script and save it as do-worldcat-search.sh
#!/bin/bash
wskey=$(<oclc-wskey.txt)
query=$1
wget "http://www.worldcat.org/webservices/catalog/search/opensearch?q="${query}"&count=100&wskey="${wskey} -O $2
Now you can execute the script as follows
chmod 744 do-worldcat-search.sh
./do-worldcat-search.sh "botanical+exploration+china" china.atom
Since the results are in Atom XML format, you can use xmlstarlet to parse them, just as you did with the Atom files returned by the Zotero server. For example, you can scan the book titles with
xmlstarlet sel -N a="http://www.w3.org/2005/Atom" -t -m "/a:feed/a:entry" -v "a:title" -n china.atom | less -NS
The WorldCat Basic API has a lot more functionality that we haven’t touched on here, so be sure to check the documentation to learn about other things that you can do with it.
Using the Springer API to find relevant sources
Since the Springer API needs a key, use vi to create a file called springer-metadata-key.txt. You can search for metadata related to a particular query using a command like the one shown below. Here we get the server to return the more human-readable JSON-formatted results as well as XML ones. Since we installed the JSONView add-on for Iceweasel, if we open the botanical-exploration.json file in our browser, it will be pretty-printed with fields that can be collapsed and expanded. Note that the metadata returned by the Springer web service includes a field that indicates whether the source is Open Access or not.
wget "http://api.springer.com/metadata/pam?q=title:botanical+exploration&api_key="$(<springer-metadata-key.txt) -O botanical-exploration.xml
less botanical-exploration.xml
wget "http://api.springer.com/metadata/json?q=title:botanical+exploration&api_key="$(<springer-metadata-key.txt) -O botanical-exploration.json
The URLs make use of the DOI (Digital Object Identifier) system to uniquely identify each resource. These identifiers can be resolved at the command line with a call from wget. Note that we create a local copy of the Springer web page when we do this. You can use your browser to open the resulting file, brittons.html. Note that this page contains references cited by the paper in human readable form, which might become useful as you further develop your workflow.
wget "http://dx.doi.org/10.1007/BF02805294" -O brittons.html




































You must be logged in to post a comment.